OmniParser for Pure Vision Based GUI Agent
With the Ferret-v2 paper, Apple demonstrated the power of building multimodal models for mobile devices. Now, Microsoft has done the same, but for the desktop UI. Presenting Omniparser, the latest advancement from Microsoft for vision-based multimodal workflows. Here is a summary in case you are interested:
Why does UI understanding matter?
Since the last few months, there has been a lot of buzz about agents and system 2. A common theme across these explorations is that we want to automate many complex yet mundane tasks with the current generation of LLMs and MLLMs.
For example, an automatic trip planner is an excellent idea. You provide the trip details e.g. starting-ending dates, places you want to explore, etc. The system takes this information as input and completes the whole task of planning the trip, including but not limited to booking flight tickets, hotels, etc.
Some of the sub-tasks in the above example can be completed using DOM alone, but things like captcha completion require visual understanding.
Hypothesis
Multimodal models like GPT-4V, when asked to predict the xy coordinates of the interactable regions on the screen directly from UI (e.g. screenshots of a web page) perform poorly because of their inability to correctly identify the semantic information associated with the icons and other elements on the screen.
Method
To elevate the above problem, the authors suggest to break down the task into two steps:
- Understand the content present on screen at the current step to figure out the interactable regions and their corresponding functionality.
- Based on the above information, predict the next action required to complete the task.
To achieve the above workflow, OmniParser combines the outputs from three different models:
- Interactable icon detection model.
- Icon description model.
- OCR module
The output is a structured DOM-like representation of the UI, with a screenshot overlaid with bounding boxes for potential interactable elements.

Interactable Region Detection
- Uses the Set-of-Marks approach to overlay bounding boxes of interactable icons on top of UI screenshots.
- Finetune a detection model to extract interactable icons/buttons.
- The authors curated a dataset of interactable icon detection dataset, containing 67k unique screenshot images, each labeled with bounding boxes of interactable icons derived from the DOM tree.
- Finetune the YOLOv8 model on the interactable icon region detection dataset for 20 epoch with a batch size of 256, learning rate of 1e−3, and the Adam optimizer on 4 GPUs.
- An OCR module is also used to extract bounding boxes of text. The authors merge the bounding boxes from the OCR detection module and icon detection module while removing the boxes that have high overlap (90% as a threshold). Every bounding box is assigned a unique ID.
Incorporating Local Semantics of Functionality
- Incorporate local semantics directly into the prompt.
- Generate a description of functionality using another model for each of the interactable regions detected by the interactable region detection model. For text boxes, detected text and the labels are injected into the prompt.
- Uses BLIP-v2 as the icon description model for generating descriptions for the interactable regions.
- For fine-tuning BLIP-v2, the authors curate a dataset of 7k icon-description pairs using GPT-4o. For the description, the authors ask GPT-4o whether the object presented in the parsed bounding box is an app icon. If GPT-4o decides the image is an icon, it outputs a sentence description of the icon about the potential functionality. And if not, GPT-4o will output ’this is not an icon’, while still including this in the dataset.
- BLIP-v2 is fine-tuned on this dataset for 1 epoch with a constant learning rate of 1e−5, no weight decay, and Adam optimizer.

Results
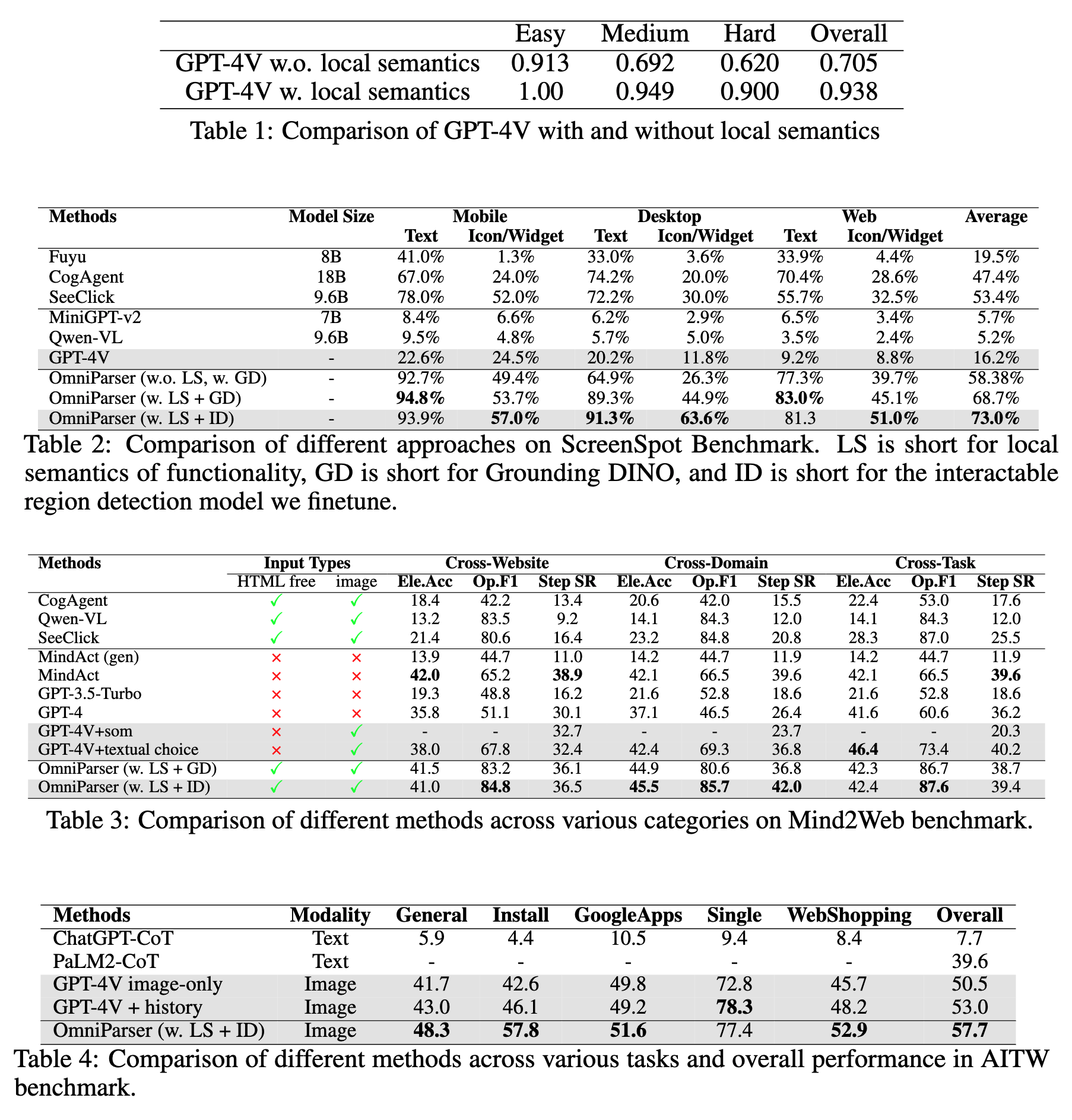
Failure Modes
- Repeated Icons/Texts: When the screenshot contains repeated elements, and it is required to click/select one of the elements, GPT-4V still fails many times. More granularity in the description of the repeated elements may alleviate the problem.
- Coarse Prediction of Bounding Boxes: The current OCR cannot differentiate between normal text and hyperlinks, hence in some cases elements of the predicted coordinatese of the clickable texts may not be correct.
- Icon Misinterpretation: Given that the icon-description model only sees a part (elements with a bbox) of the full screenshot, the lack of a global view can lead to a wrong description of the detected interactable icons. For example, three dots can be pretty confusing for the current description model
